Most solo operators inherit analytics event-naming advice from enterprise playbooks: pick a consistent schema, document it in a spreadsheet, enforce it across every tool. The promise is clarity—one event name, one definition, one source of truth.
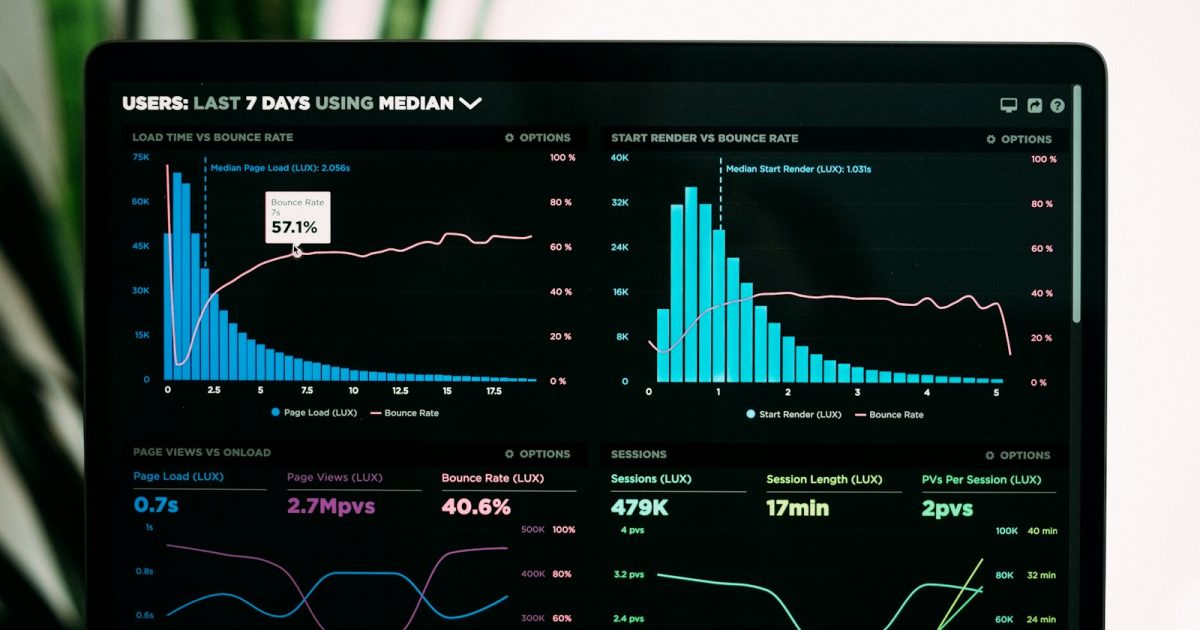
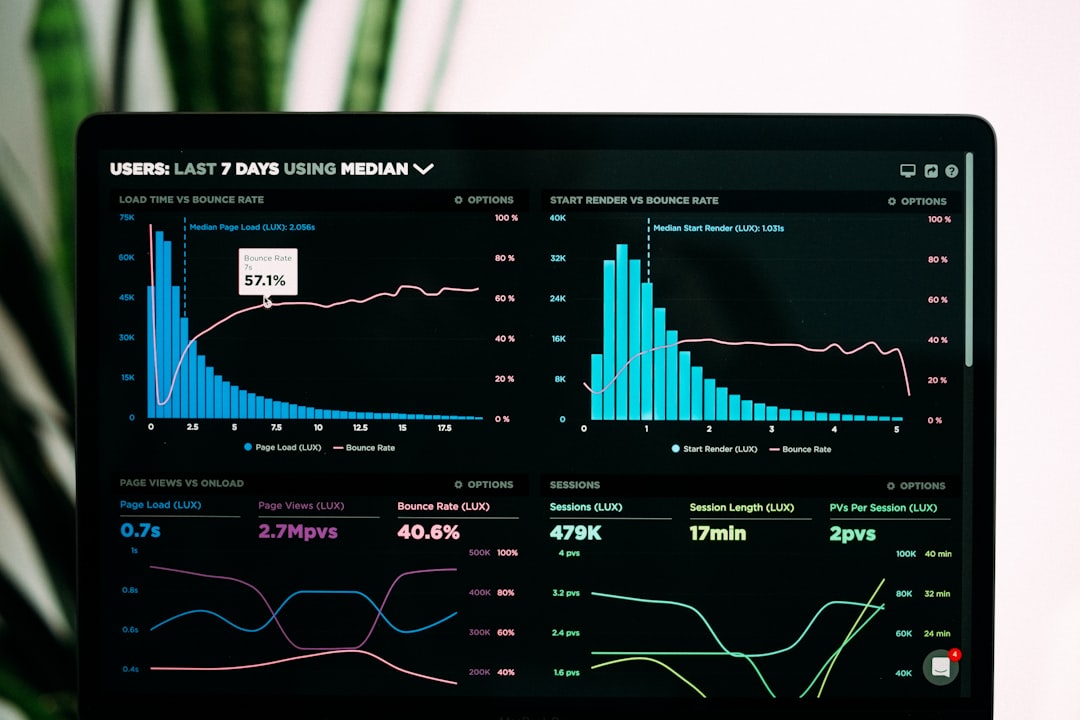
The reality is messier. When you track the same event across Google Analytics 4, a CRM, an email platform, and a payment processor, identical labels often mean subtly different things. GA4’s purchase event fires on confirmation-page load. Your payment processor’s purchase webhook fires when funds clear. Your CRM’s purchase tag triggers when a deal stage changes. None of them happen at the same moment, and none of them count the same subset of transactions.
Forcing a single name across all four systems doesn’t unify your data—it hides the gaps.
Where naming consistency helps
Event schemas make sense within a single platform. If you’re routing custom events into GA4, a predictable structure—category_action_label or verb_noun—keeps your reports readable and your segments reusable. The same applies to customer-data platforms that ingest events from multiple sources but store them in one database.
Consistency also helps when you’re debugging. If every button click follows the same pattern—click_cta_header, click_cta_sidebar—you can filter by prefix and catch tracking gaps faster.
But once you cross tool boundaries, the schema starts working against you.
The multi-tool attribution gap
Here’s the common scenario: you run a content site with a paid membership tier. A reader lands via organic search, opens three articles, clicks a paywall CTA, enters their email on a lead-magnet landing page, receives a nurture sequence, clicks a checkout link in email four, and completes payment.
GA4 sees the paywall click and the checkout page view. Your email platform (MailerLite, Postmark, ConvertKit) sees the email opens and link clicks. Your payment processor (Stripe, Lemon Squeezy) sees the transaction. If you name every conversion point conversion, your attribution report shows three separate conversions with no shared context.
You can’t merge them retroactively because the timestamps don’t align—GA4 logs in the user’s timezone, your email platform logs in UTC, and Stripe logs when the webhook fires, which might be seconds or minutes after the charge.
Naming every step conversion or purchase makes your dashboard look unified. But when you try to calculate cost-per-acquisition or attribute revenue to a specific traffic source, you’re double- or triple-counting.
Namespace by tool, not by intent
A better approach: prefix event names with the tool or surface that generated them. Instead of purchase everywhere, use:
ga4_purchasefor client-side page trackingstripe_charge_succeededfor payment webhookscrm_deal_closedfor CRM pipeline updatesemail_checkout_clickfor link tracking in transactional sequences
This naming convention makes the gaps explicit. When you run a report and see four different revenue events for the same order, you know immediately which one to trust (usually the payment processor) and which ones are proxies.
It also makes it easier to build rollup metrics. If you want a single “conversion” event that fires once per paying customer, you write a rule: count stripe_charge_succeeded, ignore everything else. You’re not guessing which purchase event is the real one.
When to break the namespace rule
There’s one case where tool-agnostic naming still makes sense: when you’re using a customer-data platform like Segment, RudderStack, or Hightouch to route events from a single source to multiple destinations.
In that setup, the CDP is the source of truth. You send one Order Completed event with a structured payload, and the CDP forwards it to GA4, your CRM, your email tool, and your data warehouse. Each destination interprets the same event in its own way, but you’re starting from a single canonical definition.
Even then, you’ll want to add destination-specific properties—GA4 needs transaction_id, Stripe needs payment_intent, your CRM needs deal_id—but the top-level event name can stay consistent.
What this means for your reporting stack
If you’ve been wrestling with attribution models that don’t add up, check your event-naming layer first. Open your GA4 events list, your email platform’s link-tracking log, and your payment processor’s webhook history. Look for overlapping names. If you see the same label in three places, assume they’re counting different things until you prove otherwise.
Then decide which tool owns the metric. Revenue attribution? That’s your payment processor. Email engagement? That’s your ESP. Page-level behaviour? That’s GA4. Name your events to reflect ownership, not aspiration.
The goal isn’t a beautiful schema—it’s a reporting stack where every number has one clear source and every query returns the same answer twice.
Got a question about analytics, attribution, or tooling for solo operators? Reply to this newsletter—we read every response and use the best ones for future deep-dives.